Prometheus and Grafana: Everything to Know for Effective Monitoring
Monitoring is the continuous observation of system metrics, logs, and operations to ensure everything functions as expected. Effective monitoring can preemptively alert you to potential issues before they escalate into major problems . It's about gaining visibility into your IT environment's performance, availability, and overall health, enabling you to make informed decisions .
Together, Prometheus and Grafana form a powerful duo. Prometheus collects and stores the data, while Grafana brings that data to life through visualization.
In this article, you'll learn about their basics and advanced features, how they complement each other , and the best practices.
I - Prometheus

Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. It excels in gathering numerical data over time, making it ideal for monitoring the performance of systems and applications. Its philosophy is centered on reliability and simplicity.
Prometheus collects and stores its metrics as time series data, metrics information is stored with the timestamp at which it was recorded, alongside optional key-value pairs called labels.
When to Use Prometheus
Prometheus excels in environments where you need to track the performance and health of IT systems and applications. It's particularly well-suited for:
- Machine-centric monitoring: Ideal for keeping an eye on the servers, databases, and other infrastructure components.
- Dynamic service-oriented architectures: Microservices and cloud-native applications benefit from Prometheus's ability to handle service discovery and frequent changes in the monitored landscape.
- Quick diagnostics during outages: Due to its autonomous nature, Prometheus is reliable when other systems fail, allowing you to troubleshoot and resolve issues swiftly.
- Situations where high precision is not critical: Prometheus is perfect for monitoring trends over time, alerting on thresholds, and gaining operational insights.
Real-life example: Consider a scenario where you have a Kubernetes-based microservices architecture. Prometheus can dynamically discover new service instances, collect metrics, and help you visualize the overall health of your system. If a service goes down, Prometheus can still function independently, allowing you to diagnose issues even if parts of your infrastructure are compromised.
When Not to Use Prometheus
However, Prometheus might not be the best fit when:
- Absolute accuracy is required: For tasks like per-request billing, where every single data point must be accounted for, Prometheus's data might not be granular enough.
- Long-term historical data analysis: If you need to store and analyze data over very long periods, Prometheus might not be the best tool due to its focus on real-time monitoring.
Real-life example: If you're running an e-commerce platform and need to bill customers for each API request, relying on Prometheus alone might lead to inaccuracies because it's designed to monitor trends and patterns, not to track individual transactions with 100% precision. In this case, you'd want a system that logs each transaction in detail for billing, while still using Prometheus for overall system monitoring and alerting.
Prometheus is good particularly when you need reliability and can tolerate slight imprecisions in favor of overall trends and diagnostics.
Architecture Overview
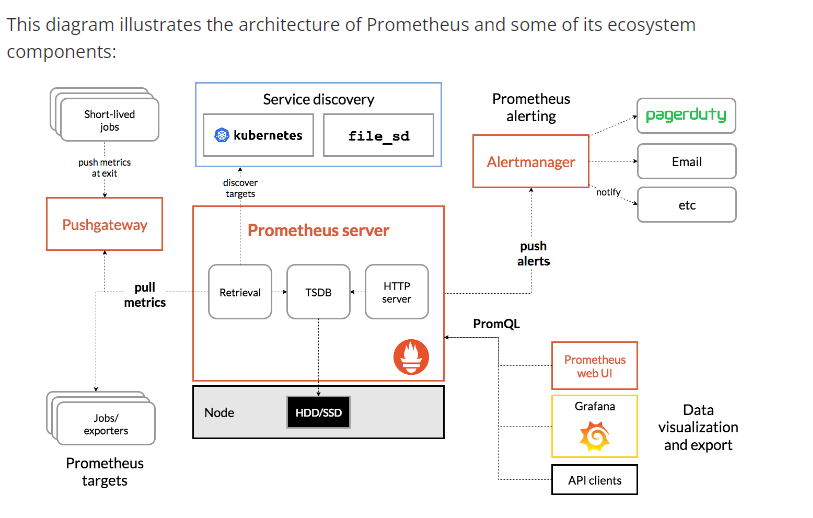
Prometheus includes several components that work together to provide a comprehensive monitoring solution:
-
Prometheus Server: The core component where data retrieval, storage, and processing occur. It consists of:
- Retrieval Worker: Pulls metrics from the configured targets at regular intervals.
- Time-Series Database (TSDB): Stores the retrieved time-series data efficiently on the local disk.
- HTTP Server: Provides an API for queries, administrative actions, and to receive pushed metrics if using the Pushgateway.
-
Pushgateway: For supporting short-lived jobs that cannot be scraped, the Pushgateway acts as an intermediary, allowing these ephemeral jobs to push metrics. The Prometheus server then scrapes the aggregated data from the Pushgateway.
-
Jobs/Exporters: These are external entities or agents that expose the metrics of your target systems (e.g., databases, servers, applications) in a format that Prometheus can retrieve. They are either part of the target system or stand-alone exporters that translate existing metrics into the appropriate format.
-
Service Discovery: Prometheus supports automatic discovery of targets in dynamic environments like Kubernetes, as well as static configuration, which simplifies the management of target endpoints that Prometheus needs to monitor.
-
Alertmanager: Handles the alerts sent by the Prometheus server. It manages the routing, deduplication, grouping, and silencing of alert notifications. It can notify end-users through various methods, such as email, PagerDuty, webhooks, etc.
-
Prometheus Web UI and Grafana: The Web UI is built into the Prometheus server and provides basic visualizations and a way to execute PromQL queries directly. Grafana is a more advanced visualization tool that connects to Prometheus as a data source and allows for the creation of rich dashboards.
-
API Clients: These are the tools or libraries that can interact with the Prometheus HTTP API for further processing, custom visualization, or integration with other systems.
Core Features

Prometheus is designed with a set of core features that make it an efficient for monitoring and alerting. These features are centered around a multi-dimensional data model, a powerful query language, and a flexible data collection approach.
- Prometheus uses a multi-dimensional data model where time series data is identified by a metric name and a set of key-value pairs, known as labels. This allows precise representation of monitoring data, enabling you to distinguish between different instances of a metric or to categorize metrics across various dimensions.
- Prometheus's data retrieval is predominantly based on a pull model over HTTP, which means that it fetches metrics from configured targets at defined intervals. However, it also offers a push model for certain use cases via the Pushgateway.
- Service discovery can automatically identify monitoring targets in dynamic environments, or through static configuration for more stable setups.
- Lastly, the built-in query language, PromQL, provides away for querying this data, allowing users to slice and dice metrics in a multitude of ways to gain insights.
These core features, when leveraged together, provide a powerful platform for monitoring at scale, capable of handling the complex and dynamic nature of modern IT infrastructure.
Metrics Collection

Instrumenting your applications is about embedding monitoring code within them so that Prometheus can collect relevant metrics. It's like giving your applications a voice, allowing them to report on their health and behavior.
To instrument an application:
- Choose Libraries: Select the appropriate client library for your programming language that Prometheus supports. For instance, if your application is written in Python, you would use the Prometheus Python client.
- Expose Metrics: Use the library to define and expose the metrics you want to monitor. These could be anything from the number of requests your application handles to the amount of memory it's using.
- Create an Endpoint: Set up a metrics endpoint, typically
/metrics, which is a web page that displays metrics in a format Prometheus understands. - Configure Scraping: Tell Prometheus where to find this endpoint by adding the application as a target in Prometheus’s configuration.
Assuming you have a Python web application and you want to expose metrics for Prometheus to scrape. You would use the Prometheus Python client to define and expose a simple metric, like the number of requests received.
Here's an example using Flask:
from flask import Flask, Response
from prometheus_client import Counter, generate_latest
# Create a Flask application
app = Flask(__name__)
# Define a Prometheus counter metric
REQUEST_COUNTER = Counter('app_requests_total', 'Total number of requests')
@app.route('/')
def index():
# Increment the counter
REQUEST_COUNTER.inc()
return 'Hello, World!'
@app.route('/metrics')
def metrics():
# Expose the metrics
return Response(generate_latest(), mimetype='text/plain')
if __name__ == '__main__':
app.run(host='0.0.0.0')
This snippet shows a simple web server with two endpoints: the root (/) that increments a counter every time it's accessed, and the /metrics endpoint that exposes the metrics.
Prometheus Configuration Example
For Prometheus to scrape metrics from the instrumented application, you need to add the application as a target in Prometheus's configuration file (prometheus.yml). Here's a simple example:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
scrape_configs:
- job_name: 'python_application'
static_configs:
- targets: ['localhost:5000']
This configuration tells Prometheus to scrape our Python application (which we're running locally on port 5000) every 15 seconds.
Service Discovery
Service discovery in Prometheus automates the process of finding and monitoring targets. It ensures Prometheus always knows what to monitor.
Prometheus supports several service discovery mechanisms:
- Static Configuration: Define targets manually in the Prometheus configuration file.
- Dynamic Discovery: Use integrations with systems like Kubernetes, Consul, or AWS to automatically discover targets as they change.
This means if a new instance of your application is up, Prometheus will automatically start monitoring it without manual intervention.
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
This code would go in your prometheus.yml file and tells Prometheus to discover all pods in a Kubernetes cluster.
Alertmanager
Alertmanager handles alerts sent by the Prometheus server and is responsible for deduplicating, grouping, and routing them to the correct receiver such as email, PagerDuty.
Here's an example alertmanager.yml configuration file for Alertmanager:
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'instance']
group_wait: 10s
group_interval: 10m
repeat_interval: 1h
receiver: 'email-notifications'
receivers:
- name: 'email-notifications'
email_configs:
- to: 'your-email@example.com'
from: 'alertmanager@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'alertmanager@example.com'
auth_identity: 'alertmanager@example.com'
auth_password: 'password'
This Alertmanager configuration sets up email notifications as the method of alerting. It groups alerts by the alertname and instance labels, waiting for 10 seconds to group them. Notifications will be sent if the group waits or group interval has passed.
By instrumenting your applications, leveraging service discovery, and configuring Alertmanager, Prometheus becomes a vigilant guardian of your infrastructure, always on the lookout for anomalies and equipped to notify you the moment something needs attention.
II - Grafana

Grafana is an open-source analytics and interactive visualization web application. It provides charts, graphs, and alerts when connected to supported data sources, including Prometheus. Essentially, Grafana allows you to turn your time-series database data into beautiful graphs and visualizations.
Overview and Core Functionalities
Grafana is known for its powerful and elegant dashboards. It is feature-rich and widely used for its:
- Dashboards: They are versatile, allowing users to create and design comprehensive overviews of metrics, complete with panels of various types that can display data from multiple sources all in one place.
- Data Sources: Grafana supports a wide array of data sources, from Prometheus to Elasticsearch, InfluxDB, MySQL, and many more. Each data source has a dedicated query editor that is customized to feature the full capabilities of the source, allowing intricate control over the data display.
- Visualization Panels: These are the building blocks of Grafana dashboards. Panels can be used to create a variety of visualization elements, from line charts to histograms and even geospatial maps.
- Annotations: This feature allows you to mark events on your graphs, providing a rich context that can be invaluable during analysis.
- Security Features: Grafana provides robust security features, including data source proxying, user roles, and authentication integrations with Google, GitHub, LDAP, and others.
Advanced Features of Grafana

While Grafana is recognized for its dashboarding capabilities, it also offers a suite of advanced features that enable more detailed data analysis and manipulation. Here are some of these features :
Query management in Explore
Explore is an ad-hoc query workspace in Grafana, designed for iterative and interactive data exploration. It is particularly useful for:
- Troubleshooting: Quickly investigate issues by freely writing queries and immediately visualizing results.
- Data exploring: Go deeper into your metrics and logs beyond the pre-defined dashboards, enabling you to uncover insights that aren’t immediately visible.
- Comparison: Run queries side by side to compare data from different time ranges, sources, or to visualize the effect of certain events.
Transformations
Transformations in Grafana allow you to manipulate the data returned from a query before it's visualized. This feature is crucial when you want to:
- Join Data: Combine data from multiple sources into a single table, which is especially useful when you're comparing or correlating different datasets.
- Calculate: Perform calculations to create new fields from the queried data, such as calculating the average response time from a set of individual requests.
- Filter and Organize: Reduce the dataset to the relevant fields or metrics, and reorganize them to suit the requirements of your visualization.
State Timeline Panel
The State Timeline panel is one of Grafana's visualizations that displays discrete state changes over time. This is beneficial for:
- Status Tracking: Monitoring the on/off status of servers, the state of feature flags, or the availability of services.
- Event Correlation: Visualizing when particular events occurred and how they correlate with other time-based data on your dashboard.
Alerting
Grafana's alerting feature allows you to define alert rules for the visualizations. You can:
- Set Conditions: Define conditions based on the data patterns or thresholds that, when met, will trigger an alert.
- Notify: Set up various notification channels like email, Slack, webhooks, and more, to inform the relevant parties when an alert is triggered.
Templating and Variables
With templating and variables :
- Create Dynamic Dashboards: Adjust the data being displayed based on user selection, without modifying the dashboard itself.
- Reuse Dashboards: Use the same dashboard for different servers, applications, or environments by changing the variable, saving time, and ensuring consistency across different views.
Best Practices

Creating dashboards that are both informative and clear is not easy. Here are some best practices:
- Clarity: Keep your dashboards uncluttered. Each dashboard should have a clear purpose and focus on the most important metrics.
- Organization: Group related metrics together. For instance, CPU, memory, and disk usage metrics could be on the same dashboard for server monitoring.
- Consistency: Use consistent naming and labeling conventions across your dashboards to make them easier to understand and use.
- Annotations: Use annotations to mark significant events, like deployments, so you can see how they affect your metrics at a glance.
- Interactivity: Use Grafana’s interactive features like variables to allow users to explore data within the dashboard.
- Refresh Rates: Set reasonable dashboard refresh rates to ensure up-to-date data without overloading your data source or Grafana server.
Naming Conventions for Metrics
Consistent naming conventions are crucial. They ensure that metrics are easily identifiable, understandable, and maintainable. For instance, a metric name like http_requests_total is clear and indicates that it’s a counter metric tallying the total number of HTTP requests.
Efficient Querying
For efficient PromQL queries:
- Be Specific: Craft your queries to be as specific as possible to fetch only the data you need.
- Use Filters: Apply label filters to reduce the data set and increase query speed.
- Avoid Heavy Operations: Functions like
count_over_timecan be resource-intensive. Use them judiciously. - Time Ranges: Be cautious with the time range; querying a massive range can lead to high load and slow responses.
Security Considerations
For security in Prometheus and Grafana:
- Data Encryption: Use HTTPS to encrypt data in transit between Prometheus, Grafana, and users.
- Access Control: Implement strict access controls in Grafana, with different user roles and permissions.
- Authentication: Use Grafana’s built-in authentication mechanisms, or integrate with third-party providers.
- Regular Updates: Keep Prometheus and Grafana up to date with the latest security patches.
By integrating Prometheus with Grafana following these best practices, you can create a monitoring environment to your systems in a secure, efficient, and user-friendly manner. This combination can be a powerful asset in any infrastructure, enabling teams to detect and address issues proactively.
III - Conclusion

Grafana makes sense of all the numbers Prometheus collects by turning them into easy-to-read dashboards and graphs. This makes it easier for you to see what's going on and make smart decisions.
However, Prometheus isn't great for everything. If you need to track every tiny detail for things like billing, it's not the best choice. It's better for looking at overall trends and issues.